This is a recent paper I wrote with my advisor Dr. Mihai Nica (Professor of Mathematics, University of Guelph), which was accepted to the 2023 International Conference on Machine Learning for the High Dimensional Learning Dynamics workshop. This work builds off of our previous paper Depth Degeneracy in Neural Networks: Vanishing Angles in Fully Connected ReLU Networks on Initialization (arXiv link), and uses our previous theoretical results in an applied setting to study training dynamics of deep ReLU networks.
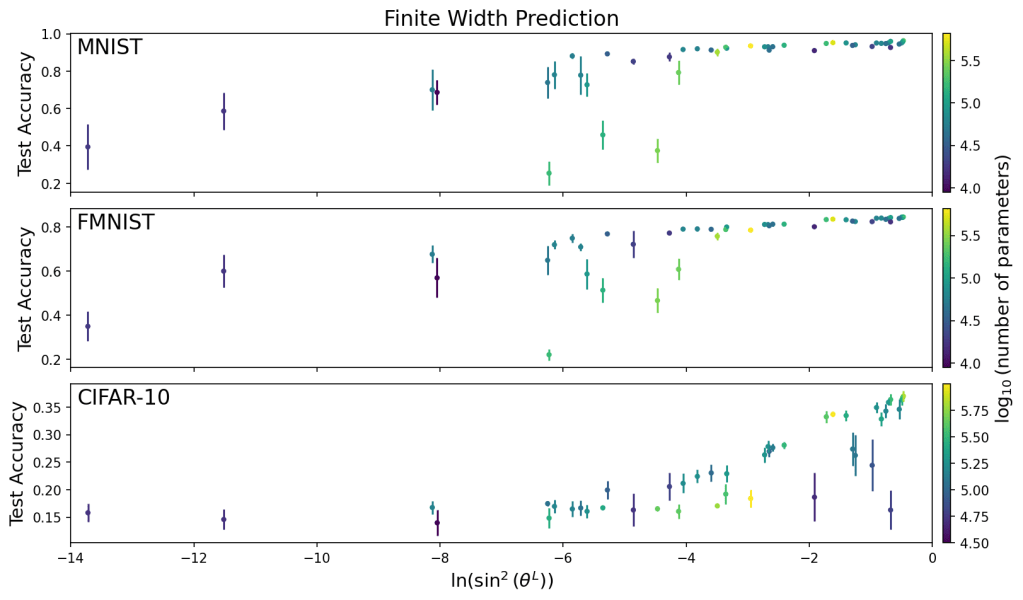
In our previous work, we found a simple and accurate algorithm to predict the level of “degeneracy” in a fully connected ReLU network, using only the network architecture. We observe this degeneracy in the sense that on initialization, deep networks tend to make inputs more and more correlated as they travel through the network. If the network architecture causes inputs to be very highly correlated, the network will likely have a hard time distinguishing the difference between inputs, which in turn makes the network harder to train. In this paper, we run simulations to study the relationship between network degeneracy and training performance. We also cover our simple algorithm developed to predict degeneracy in finite width networks, and show that it performs better than using prediction methods developed for infinite width networks.
This paper can found on the arXiv, and code to produce Figure 1 can be found on my GitHub.
